Hallo,
habe das Problem, das auf einmal das System voll war.
Bis heute morgen lief alles einwandfrei und ab 11 Uhr kam ich nicht mehr auf das Webinterface. Habe dann auch rausgefunden, dass die Partition wohl voll ist und die logs soweit wie möglich gelöscht. Nun sind wieder 80% Verfügbar.
derzeit sieht es so aus:
tmpfs 1,0G 14M 1011M 2% /RAMDISK
/dev/sda1 479M 305M 150M 68% /SYSTEM
/dev/sda2 4,4G 820M 3,4G 20% /CUSTOM
/dev/sda3 5,1G 1,5G 3,4G 31% /BACKUP
/dev/cloop 756M 756M 0 100% /FIRMWARE
unionfs 1,0G 14M 1011M 2% /TARGET
unionfs 4,4G 820M 3,4G 20% /TARGET/etc
unionfs 4,4G 820M 3,4G 20% /TARGET/var
df: â/TARGET/dev/.static/devâ: Keine Berechtigung
tmpfs 10M 52K 10M 1% /TARGET/dev
tmpfs 505M 4,0K 505M 1% /TARGET/dev/shm
Es waren wohl zwei riesige Log Dateien. Leider weiß ich nicht mehr genau wo die waren, ich glaube eine war in var/log/asterisk.
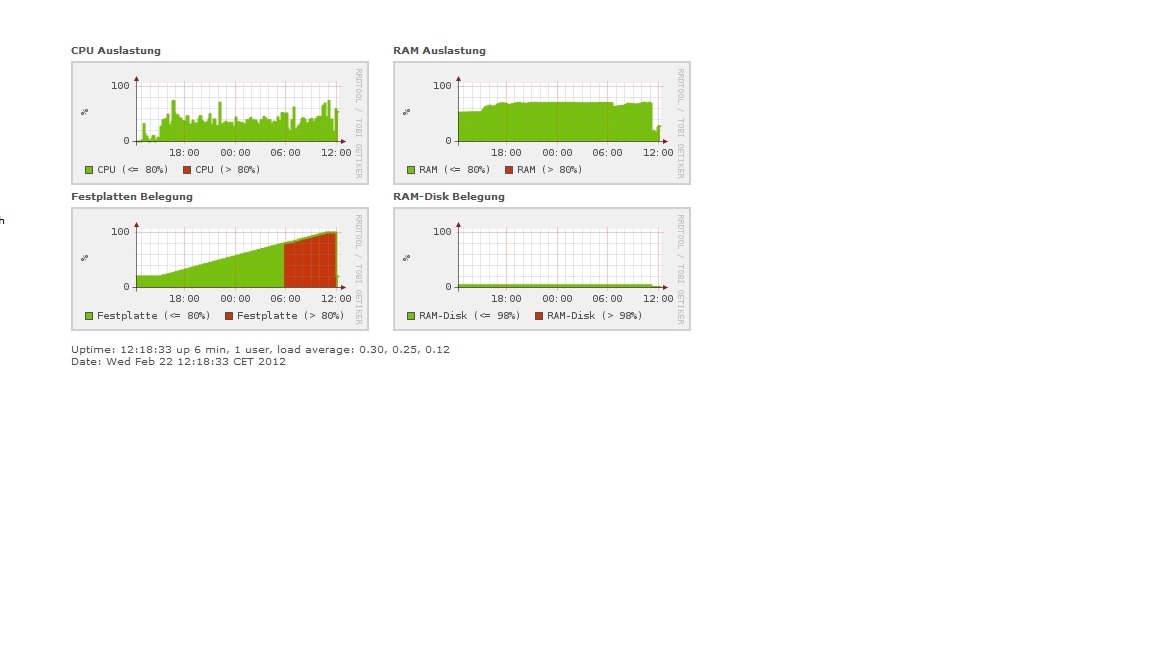
Was kann hierfür die Ursache sein? Und wie kann man das verhindern?
Grüße
Andi