Da um diese Uhrzeit niemand aktiv ist, stört das nicht weiter. Seltsam ist nur, warum kommt es erst nach diesem Update? Wurde etwas am Backup-Prozess verändert?
Vereinzelt kommen NTP-Probleme von Incinga auch erst nach dem Update:
Einen Tag nach dem Update versuchte die MobyDick direkt eine Mail zu senden:
Subject: Cron <root@mobydick> /usr/bin/exdjob.pl tsk020506 ‘100203||’
Content-Type: text/plain; charset=UTF-8
X-Cron-Env: <SHELL=/bin/sh>
X-Cron-Env: <HOME=/root>
X-Cron-Env: <PATH=/usr/bin:/bin>
X-Cron-Env: <LOGNAME=root>
DBD::SQLite::st execute failed: disk I/O error at /usr/lib/perl5/exdjobs.pm line 90.
Weiter ist uns nach dem Update bereits zwei Mal der XMPP-Server abgestürzt.
bezüglich der load kann ich dich dann beruhigen. Das ist ein problem der Microsoft-HyperV-Treiber für den Linux-Kernel in unserer Kernelversion. Die hohe Load ist nicht tatsächlich vorhanden sondern es ist ein reines Anzeigeproblem. Da sich der Icinga allerdings auf diese Anzeigen verlässt, schlägt er öfters mal an. (Das ergaben zumindest unsere Tests auf einem 2012R2. Aber ich vermute das es sich bei 2008 sehr ähnlich verhält.)
Zu dem anderen Problem: Das sieht nach einem Festplattenfehler aus. Sie doch mal mit dmesg und im syslog nach, ob da irgendetwas auffälliges passiert.
mmh, kann ich nicht ganz teilen.
Steigt die Load weiter, ist das System nicht mehr zu benutzen. Sprich Gespräche sind enorm gestört oder brechen ganz ab, Anwahlen sind nicht mehr möglich, etc. Vergleiche ich zum Beispiel via top die Loads auf der Console, laufen Installationen in virtuellen Maschinen immer deutlich höher als eine Installation auf nativer Hardware obwohl die virtuellen Maschinen sogar noch zwei Prozessorkerne mehr haben. Der 15-Minuten-Schnitt der “Load average” mit 2 Prozessorkernen liegt auf einer direkten Hardwareinstallation bei ca. 0,15, bei der virtualisierten Versionen mit 4 Prozessorkernen bei ca. 0,9.
Dem Syslog konnte ich nichts Auffälliges entnehmen.
Steigt die Load weiter, ist das System nicht mehr zu benutzen. Sprich Gespräche sind enorm gestört oder brechen ganz ab, Anwahlen sind nicht mehr möglich, etc.
Das ändert die Situation natürlich, ich dachte bisher das du nur Meldungen vom Icinga bekommst. - So war es zumindest bisher in unseren Tests, und da war die Telefonie nicht beeinträchtigt.
Wie viele Benutzer sind auf dem System?
Was sind die Eckdaten der VM (CPU (Kerne), RAM, HDD, Netzwerkschnittstellen, etc.?)
Was sind die Eckdaten des HyperV-Servers, wieviele VMs laufen sonst noch da drauf?
Dein “Problem #3” könnte zumindest theoretisch auch durch die hohe Load verursacht werden.
lass mich vorwegnehmen, dass wir bisher mit keiner Hyper-V-VM irgendwelche besseren Ergebnisse erzielen konnten. Das Problem beschränkt sich daher - meiner Meinung nach - nicht auf eine einzelne Hyper-V. Die Nachricht, dass ihr künftig mehr Hardwareplattformen bzw. Geräte unterstützen möchtet, kommt da sehr gelegen.
Zu deinen Fragen. Hier als Beispiel ein Hyper-V-Server mit dem es gar nicht mehr ging:
Im Schnitt 20 User
4 Kerne, 4GB RAM, Dynamische VHD, eigene Gigabit-Netzwerkkarte
DL380 G5: 1x Intel Xeon E5335 (4 Kerne), 6GB RAM, RAID 5 aus 4x 146 GB SAS, VM: Nur MobyDick
Die derzeitigen Probleme haben wir aber auf deutlich “größerer” Hardware wie:
ML350 G6: 2x Intel Xeon E5645 (24 Kerne), 48GB RAM, RAID 5 aus 4x 300 GB SAS, 3 weitere VMs
Ich bin jedoch der Meinung, dass es nicht an Hardware-Ressourcen liegt. Denn nativ läuft eine MobyDick mit 20 Usern auch auf einem Desktop-Rechner.
in der Virtualisierung ist “weniger manchmal mehr”. Verringere bitte einmal die virtuellen CPU´s von vier auf eine bzw. zwei. Ebenso den RAM von 4GB auf 2GB herunter setzten.
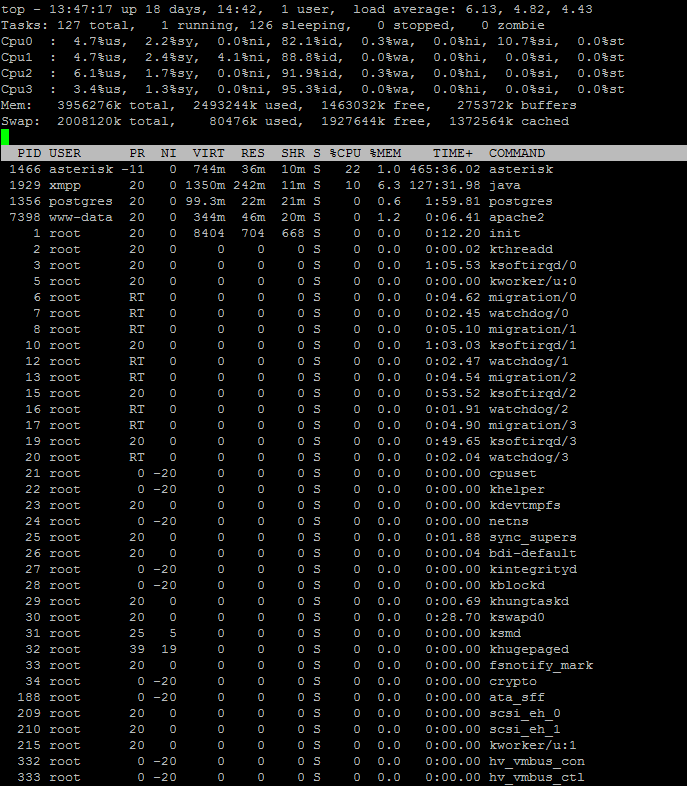
wir haben heute mal die Anlage mit ein wenig Inbound befeuert. Gleichzeitig schneiden wir Gespräche mit. Anbei mal der Auswurf von “top”.
Icinga läuft Amok.
nur für unsere weitere Planung:
Denkst du, das ihr hier in Kürze (1-2 Monate) zum Testen oder gar zu einer Lösung kommt oder sollen wir auf alternative Virtualisierungslösungen oder gar native Hardware ausweichen?
also was unsere Recherche ergab, ist das load-problem tatsächlich rein kosmetisch. Scheint auch von Microsoft-Mitarbeitern selbst bestätigt zu werden. Auch einige unserer größeren haben Kunden HyperV-basierte Appliances im Einsatz. Diese zeigen auch erhöhte load Werte im top, laufen aber ansonsten Problemfrei.
Deine Probleme auf den virtualisierten Appliances müssen eigentlich eine andere Ursache (möglicherweise Netzwerkprobleme?) haben. Wenn du bei deinem speziellen schnelle Hilfe benötigst, eröffne bitte ein (kostenpflichtiges) Support-Ticket.
das hatten wir im März bereits. Ticket-ID: 1017542. Allerdings ohne Erfolg.
Netzwerkprobleme kann ich ausschließen. Weiter fallen die Ausfälle genau mit den Load-Peaks (Icinga & top) zusammen. Was mich darin bestärkt, dass es nicht nur kosmetischer Natur ist. Wie sind die Erfahrungen mit Hyper-V unter 2012 R2 oder gar Citrix Xen?
wir haben heute im Meeting die ganze Situation noch einmal durchgesprochen.
Hier unsere Erkenntnisse: Es gibt nach wie vor ein kosmetisches Problem bei der Anzeige der load. Dieses hat nach unseren Tests keine Auswirkungen auf Anrufe o. ä.
Die Ursache für dieses Anzeigeproblem liegt bei den Microsoft-HyperV-Treibern für den Linux-Kernel. Diese haben in der Version die wir (bzw. debian oldstable) einsetzen, einen Bug der zur fehlerhaften Anzeige führt.
zur MobyDick 7.09 werden wir aber den Kernel (und damit auch die Treiber) des Systems gegen eine etwas neuere Version tauschen, diese sollte die besagten Anzeigeprobleme nicht mehr haben.
danke für die Zwischenmeldung.
Ist davon auszugehen, dass dann auch Incinga keine “falschen” Warnungen mehr ausgibt? Ich bekomme jede Nacht nach wie vor die drei Mails zur Backupzeit (siehe Einganspost Punkt 1).
Die beschriebene Mail aus Punkt 3 ist bisher noch ein weiteres Mal gekommen.
Abstürze des XMPP-Servers (Punkt 4) hatten wir in der Vergangenheit immer mal wieder. Besonders dann, wenn an der Anlage Konfigurationen im Commander (welche ausdrücklich keinen Neustart des XMPP-Servers erfordern) durchgeführt werden. Das ist natürlich sehr ärgerlich, wenn einem dann alle Call Center Agenten auf einen Schlag wegbrechen.
da der Icinga sich auch auf die fehlerhafte load Ausgabe verlässt, sollten diese Meldungen nichtmehr auftreten.
Zu Punkt 3: Wir hatten das Problem sehr sporadisch, ohne das es größere Auswirkungen gehabt hätte. Hast du irgendwelche Logfiles zu dem Zeitpunkt an dem das Auftritt das wird das näher verfolgen können?
Zu Punkt 4: Das der XMPP Server stürzt ist natürlich sehr schade, aber ohne weitere Informationen kann ich dir da nicht helfen. Welche Konfiguration hast du durchgeführt? Kannst du uns die XMPP-Server-Logs zum Absturzzeitpunkt zukommen lassen?